Python 在科研中的应用 10:Python 环境下的数字图像目标检测

计算机视觉中的“目标检测”是指使用计算机视觉技术来识别图像或视频帧中的对象,并确定它们的位置。目标检测系统通常包括一个预处理步骤,用于改善图像质量,然后是特征提取,用于从图像中提取有用的信息。接下来,一个分类器会被用来确定图像中是否存在特定的对象。最后,一个定位器会提供一个边界框或更精确的轮廓来标记对象的位置。目标检测在自动驾驶、视频监控、医疗成像和许多其他应用中都有广泛的应用。
课程作业 占总成绩25%
给你一个长度为 n 的字符串 moves,该字符串仅由字符L、R和_组成。字符串表示你在一条原点为 0 的数轴上的若干次移动。
你的初始位置就在原点(0),第 i 次移动过程中,你可以根据对应字符选择移动方向:
如果 moves[i] = 'L' 或 moves[i] = '_',可以选择向左移动一个单位距离
如果 moves[i] = 'R' 或 moves[i] = '_',可以选择向右移动一个单位距离
移动 n 次之后,请你找出可以到达的距离原点 最远 的点,并返回 从原点到这一点的距离 。
Harris 角点检测算法

代码示例
1 | import numpy as np |



通常,我们依据以下方式判断二维图像中的三种特征区域:
(1)平坦区域:以该点为中心沿任意方向的图像灰度梯度均较小。
(2)角点区域:以该点为中心沿任意方向的图像灰度梯度均较大。
(3)棱边区域:以该点为中心沿特定方向的图像灰度梯度较大,沿其正交方向图像灰度梯度较小。

这与上图中展示的三种区域的典型示例相匹配。Harris提出针对含有独特纹理特征的二维图像,利用基于其局部自相关函数的角点检测算子。它可以准确地检测出图像结构中的角点、棱边以及平坦区域。局部自相关性的定义为:
\begin{equation}
\label{harrisS1}
e(x,y) = \sum_{x_i,y_i} W(x_i,y_i)[I(x_i+\Delta x,y_i+\Delta y)-I(x_i,y_i)]^2,
\end{equation}
这里$I(x_i,y_i)$为二维图像的灰度值,$W(x_i,y_i)$为以点$(x,y)$为中心的高斯函数在点$(x_i,y_i)$处的取值,高斯函数的半高全宽直接决定了检测算子的影响区域半径。$(\Delta x,\Delta y)$为$(x,y)$点指向$(x_i,y_i)$点的二维矢量。
将公式\ref{harrisS1}泰勒展开并保留到一阶分量有:
\begin{equation}
e(x,y) = \hat{S} \begin{bmatrix} \sum_{x_i,y_i} W\cdot I_x^2 & \sum_{x_i,y_i} W\cdot I_x\cdot I_y \\ \sum_{x_i,y_i} W\cdot I_x\cdot I_y & \sum_{x_i,y_i} W\cdot I_y^2 \end{bmatrix} \hat{S}^T = \hat{S}\cdot E(x,y)\cdot\hat{S}^T,
\end{equation}
这里$\hat{S} = (\Delta x,\Delta y)$表示偏移矢量,$I_x,I_y$分别为初始二维图像$I(x,y)$沿$x,y$两个方向的偏微分。

Harris与Stephens教授提出可以通过分析矩阵$E$的一对特征值$\alpha,\beta$的特性来判别角点、棱边和平坦区域,这对特征值包含了足够的与邻域特征有关的局部结构信息。例如,当位于角点区域时,特征值$\alpha,\beta$均较大;而当位于棱边区域时,特征值$\alpha,\beta$总有一个较大而另一个较小;当位于平坦区域时,特征值$\alpha,\beta$均极小。根据这样的特性,Harris提出角点判别指标:
\begin{equation}
h(x,y) = {\rm Det}(E)-k\cdot {\rm Tr}(E)^2 = \alpha\beta - k\cdot(\alpha\beta)^2,
\end{equation}
这里,$k$为自适应参数。判别指标$h(x,y)$的等高线通过图\ref{harris02}中的细线表示,根据上图判断,$h(x,y)$值接近0时,为平坦区域;$h(x,y)$值大于0时,为角点区域;$h(x,y)$值小于0时,为棱边区域。

Harris教授提出的方法在二维自然图像中能够获得优异的准确性与鲁棒性。然而当我们面临三维结构图像时,逻辑出现了本质的不同。在三维空间中,区域的分类出现了四种情况,分别是:孔隙、胞壁、棱边、角点区域,它们分别对应于3、2、1和0个维度的平移不变性。当我们考虑如何分离这四种区域时,我们可以从Harris指标的形式出发将其扩展至三维空间;或是从三维灰度图像出发,将三维图像分解为一幅幅二维图像并在二维图像中处理问题。这里作者选择了第二种方案,并取得了有效的结果。
Corner with SubPixel Accuracy
1 | import numpy as np |
尺度不变特征变换匹配(SIFT)算法
尺度不变特征变换匹配(Scale Invariant Feature Transform, SIFT)算法,是David G. Lowe[1]在1999年提出的高效区域检测算法,2004年[2]完善。SIFT算法将图像中检测到的特征点用128维的特征向量进行描述。其本质是在不同的空间尺度上查找特征点,并计算特征点方向。SIFT算法所查找到的特征点是一些十分突出的局部结构,对旋转、尺度缩放、亮度变化等保持不变性,对于光照、仿射和投影变换也有一定的不变性,是目前领域内非常成熟稳定的局部特征检测算法。
代码实现
1 | import cv2 |
1 | import cv2 |
逻辑框架
Lowe教授将SIFT算法分解为如下四步:
- 尺度空间极值检测:搜索所有尺度上的图像位置。通过高斯微分函数来识别潜在的对于尺度和旋转不变的兴趣点。
- 特征点精确定位:在每个候选的位置上,通过精细拟合模型确定位置和尺度。特征点的选择依赖它们的稳定程度。
- 方向确定:基于图像局部梯度方向,分配给每个特征点位置一个或多个方向。所有后面的对图像数据的操作都相对于关键点的方向、尺度和位置进行变换,从而提供对于这些变换的不变性。
- 特征点描述:在每个关键点周围的邻域内,在选定的尺度上测量图像局部的梯度。这些梯度被变换成一种表示,这种表示允许比较大的局部形状的变形和光照变化。
SIFT算法原理
尺度空间极值检测
尺度空间理论
尺度越大图像越模糊。用机器视觉系统分析未知场景时,计算机并不预先知道图像中物体的尺度。我们需要同时考虑图像在多尺度下的描述,获知感兴趣物体的最佳尺度。另外如果不同的尺度下都有同样的关键点,那么在不同的尺度的输入图像下就都可以检测出来关键点匹配,也就是尺度不变性。 图像的尺度空间表达就是图像在所有尺度下的描述。
高斯模糊
高斯核是唯一可以产生多尺度空间的核。一个图像的尺度空间$L(x,y,\sigma)$,定义为原始图像$I(x,y)$与一个可变尺度的2维高斯函数$G(x,y,\sigma)$的卷积运算。二维空间高斯函数:
\begin{equation}
G(x_i,y_i,\sigma)=\frac{1}{2\pi\sigma^2}{\rm exp}\left[-\frac{(x-x_i)^2+(y-y_i)^2}{2\sigma^2}\right]
\end{equation}
尺度空间为:
\begin{equation}
L(x,y,\sigma)=G(x,y,\sigma)*I(x,y)
\end{equation}
在二维空间中,这个公式生成的曲面的等高线是从中心开始呈正态分布的同心圆。分布不为零的像素组成的卷积矩阵与原始图像做变换。每个像素的值都是周围相邻像素值的高斯加权平均。中心像素的值有最大的高斯分布值,所以有最大的权重,相邻像素随着距离中心像素越来越远,其权重也越来越小。这样进行模糊处理比其它的均衡模糊滤波器更高地保留了边缘效果。$\sigma$越大,中心像素的权重与周围像素就会相对越小,加权平均后就会越模糊;反之,$\sigma$越小,中心像素权重相对越大,当$\sigma=0$时,就是原图的样子,相当于周围像素对新图没有贡献。换句话说,大尺度对应于图像的概貌特征,小尺度对应于图像的细节特征。理论上来讲,图像中每点的分布都不为零,这也就是说每个像素的计算都需要包含整幅图像。在实际应用中,在计算高斯函数的离散近似时,在大约$3\sigma$距离之外的像素都可以看作不起作用,这些像素的计算也就可以忽略。通常,图像处理程序只需要计算$(6\sigma+1)^2$的矩阵就可以保证相关像素影响。
金字塔多分辨率
与多尺度空间相对的,金字塔是早期图像多尺度的表示方式。图像金字塔化一般两个步骤:
- 使用低通滤波器(LPF)平滑图像;
- 平滑图像降采样(通常
该方式能得到系列尺寸缩小的图片。尺度空间表达和金字塔分辨率表达的明显区别有:
- 尺度空间表达是由不同高斯核平滑卷积得到的,在所有尺度上分辨率相同;
- 金字塔多分辨率表达每层分辨率减少固定比率。
因此,金字塔多分辨率生成快,空间少,但局部特征描述单一;多尺度空间的图片局部特征可以在不同尺度描述,但随尺度参数增加会增加冗余信息。
高斯金字塔
高斯金字塔是最基本的图像塔。原理:首先将原图像作为最底层图像 level0(高斯金字塔的第0层),利用高斯核(5$*$5)对其进行卷积,然后对卷积后的图像进行下采样(去除偶数行和列)得到上一层图像G1,将此图像作为输入,重复卷积和下采样操作得到更上一层的图像,反复迭代多次,形成一个金字塔形的图像数据结构,即高斯金字塔。高斯金字塔是在sift算子中提出来的概念,首先高斯金字塔并不是一个金字塔,而是由很多组(Octave)金字塔构成,并且每组金字塔都包含若干层(Interval),即在同一组的金字塔中,使用不同$\sigma$进行高斯模糊,然后再不同组的金字塔中,使用下采样,获得不同分辨率的图像。
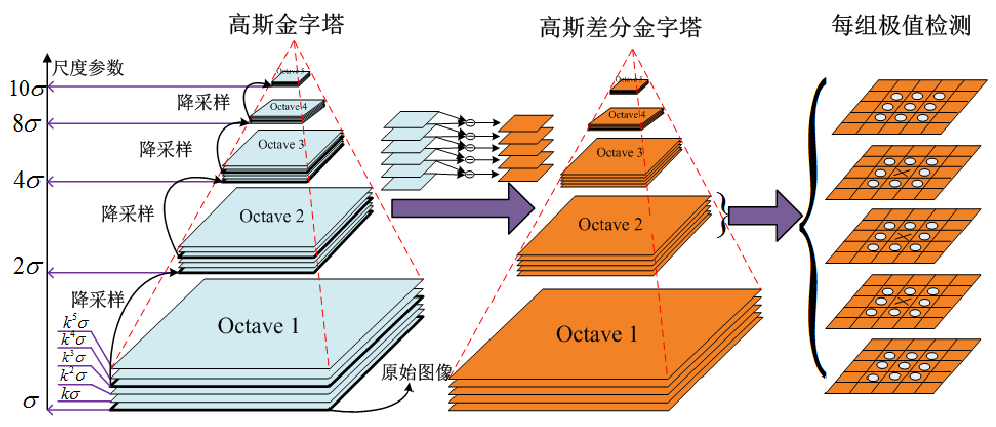
高斯金字塔的构建过程:
- 先将原图像扩大一倍之后作为高斯金字塔的第1组第1层,将第1组第1层图像经高斯卷积(高斯平滑或称高斯滤波)之后作为第1组金字塔的第2层。对于参数$\sigma$,在SIFT算子中取的是固定值 1.6;
- 将$\sigma$乘以一个比例系数$k$,得到新的平滑因子$\sigma=k*\sigma_{old}$,用它来平滑第1组第2层图像,结果图像作为第3层。
- 如此重复,最后得到L层图像,在同一组中,每一层图像的尺寸都是一样的,只是平滑系数不一样。它们对应的平滑系数分别为:$0,\sigma,k\sigma,k^2\sigma,k^3\sigma……k^{(L-2)}\sigma$。
- 将第1组倒数第三层图像作为比例因子为2的降采样,得到的图像作为第2组的第1层,然后对第2组的第1层图像作平滑因子为$\sigma$的高斯平滑,得到第2组的第2层,就像步骤2中一样,如此得到第2组的L层图像,同组内它们的尺寸是一样的,对应的平滑系数分别为:$0,\sigma,k\sigma,k^2\sigma,k^3\sigma……k^{(L-2)}\sigma$。但是在尺寸方面第2组是第1组图像的一半。这样反复执行,就可以得到一共$O$组,每组$L$层,共计$O*L$个图像,这些图像一起就构成了高斯金字塔。在同一组内,不同层图像的尺寸是一样的,后一层图像的高斯平滑因子是前一层图像平滑因子的$k$倍;在不同组内,后一组第一个图像是前一组倒数第三个图像的二分之一采样,图像大小是前一组的一半。
高斯拉普拉斯金字塔
LoG(Laplace of Gaussian)是对高斯函数进行拉普拉斯变换:
\begin{equation}
L(x,y,\sigma)=\frac{\partial^2G}{\partial x^2} + \frac{\partial^2G}{\partial y^2}
\end{equation}
拉普拉斯金字塔用于重建图形,也就是预测残差,对图像进行最大程度的还原。比如一幅小图像重建为一幅大图。原理:用高斯金字塔的每一层图像减去其上一层图像上采样并高斯卷积之后的预测图像,得到一系列的差值图像,即为Laplacian分解图像。
LoG第$i$层的数学定义:
\begin{align}
L_i &= G_i-Up(G_{i+1})\otimes g \
&=G_i - PyrUp(G_{i+1}) \
\end{align}
式中,$G_i$表示高斯金字塔中第层图像。也就是说,拉普拉斯金字塔是通过高斯金字塔图像减去先缩小(即上一层图像)后再放大(即上采样操作)并高斯卷积后的图像的一系列图像构成的。
高斯差分金字塔
LoG的主要缺点是需要求二阶导,计算较复杂,因此我们就想用别的算子去近似它。DoG(Difference of Gaussian),相当于对LoG的近似计算,SIFT算法中建议某一尺度的特征检测,可以通过两个相邻高斯尺度空间的图像相减,得到DoG的响应值图像。DoG和LoG的关系如下述所示:
\begin{equation}
\sigma\nabla^2G = \frac{\partial G}{\partial\sigma} \approx \frac{G(x,y,k\sigma) - G(x,y,\sigma)}{k\sigma - \sigma}
\end{equation}
因此,有:
\begin{equation}
G(x,y,k\sigma) - G(x,y,\sigma) \approx (k-1)\sigma^2\nabla^2G
\end{equation}
而$\sigma^2\nabla^2G$正是尺度归一化算子的表达形式。在所有的尺度中$k-1$是一个常数,当$k$趋近于1的时候误差趋近于0,但实际上这种误差对于极值的位置检测并没有什么影响(不过前人的实验证明LoG提取的特征稳定性最强)。
空间极值点检测
SIFT关键点是由DOG空间的局部极值点组成的,关键点的初步探查是通过同一组内各DoG相邻两层图像之间比较完成的。极值点定义:每一个像素点与它所有相邻点比较,当其大于(或小于)它的图像域和尺度域的所有相邻点时,即为极值点。为了寻找DoG函数的极值点,每一个像素点要和它所有的相邻点比较,看其是否比它的图像域和尺度域的相邻点大或者小。如下图所示,中间的检测点和它同尺度的8个相邻点和上下相邻尺度对应的9×2个点共26个点比较,以确保在尺度空间和二维图像空间都检测到极值点。
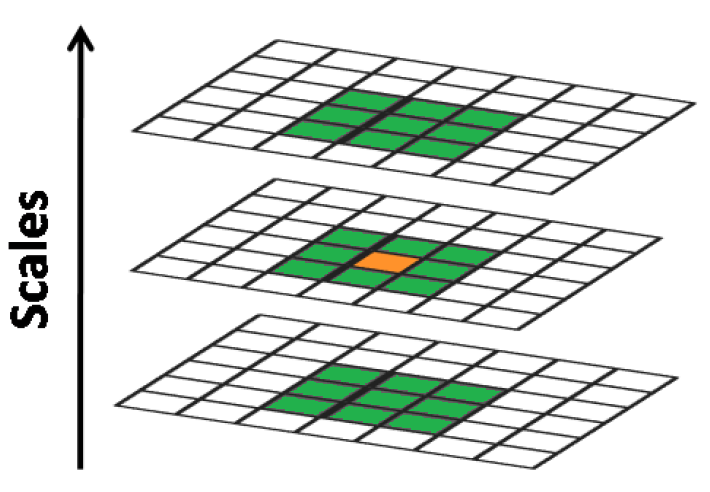
由于要在相邻尺度进行比较,那么对于高斯差分金子塔中的每一组的所有层,只能在中间两层中进行两个尺度的极值点检测,其它尺度则只能在不同组中进行。为了在每组中检测$S$个尺度的极值点,则DOG金字塔每组需$S+2$层图像,而DOG金字塔由高斯金字塔相邻两层相减得到,则高斯金字塔每组需$S+3$层图像,实际计算时$S$在3到5之间。当然这样产生的极值点并不全都是稳定的特征点,因为某些极值点响应较弱,而且DOG算子会产生较强的边缘响应。
到这里,总结一下,构建DOG尺度空间金字塔的三个重要参数是:尺度$\sigma$、组(octave)数$O$和组内层数$S$。
特征点精确定位
计算机中存储的图像数据是离散的,而我们之前找到的极值点也就是离散空间中的极值点,但是离散空间中的极值点并不是真实的连续空间中的极值点。所以需要对DoG空间进行拟合处理,以找到极值点的精确位置和尺度。另外,我们还需要去除那些在边缘位置的极值点,以提高关键点的稳定性。
精确定位

利用已知的离散空间点插值得到连续空间极值点的方法叫做子像元插值。
在Lowe的论文中,使用的是泰勒展开式作为拟合函数。
通过上步的极值点检测,我们得到的极值点是一个三维向量,包括它所在的尺度$\sigma$以及所在尺度图像中的位置坐标$(x,y)$。设$X_0 = (x_0,y_0,\sigma_0)$,则泰勒展开的矩阵表示为:
\begin{equation}
f(\left[\begin{matrix}x\y\\sigma\end{matrix}\right]) \approx f(\left[\begin{matrix}x_0\y_0\\sigma_0\end{matrix}\right]) + \left[\frac{\partial f}{\partial x} \frac{\partial f}{\partial y} \frac{\partial f}{\partial \sigma}\right]\left[\begin{matrix}x-x_0\y-y_0\\sigma-\sigma_0\end{matrix}\right] + \frac{1}{2}\left[\begin{matrix}x-x_0\y-y_0\\sigma-\sigma_0\end{matrix}\right]^{\rm T}\left[\begin{matrix}
\frac{\partial^2 f}{\partial x^2} & \frac{\partial^2 f}{\partial x \partial y} & \frac{\partial^2 f}{\partial x \partial \sigma} \
\frac{\partial^2 f}{\partial x \partial y} & \frac{\partial^2 f}{\partial y^2} & \frac{\partial^2 f}{\partial y \partial \sigma} \
\frac{\partial^2 f}{\partial x \partial \sigma} & \frac{\partial^2 f}{\partial y \partial \sigma} & \frac{\partial^2 f}{\partial \sigma^2} \
\end{matrix}\right]\left[\begin{matrix}x-x_0\y-y_0\\sigma-\sigma_0\end{matrix}\right]
\end{equation}
若写成矢量形式,则为:
\begin{equation}
f(X) = f(X_0)+\frac{\partial f^{\rm T}}{\partial X}(X- X_0)+\frac{1}{2}(X-X_0)^{\rm T}\frac{\partial^2 f}{\partial X^2}(X-X_0)
\end{equation}
在这里$X_0$表示离散的插值中心,$X$表示拟合后连续空间的插值点坐标,则设$\hat{X}=X-X_0$,表示偏移量,带入上式,另求得的导数为0(求一阶导等于0得到的点就是极值点),则有:
\begin{equation}
\hat{X} = -\frac{\partial^2 f^{-1}}{\partial X^2}\frac{\partial f}{\partial X}
\end{equation}
只要上式中得到的偏移量大于0.5,则认为偏移量过大,需要把位置移动到拟合后的新位置,继续进行迭代求偏移量,若迭代过一定次数后偏移量仍然大于0.5,则抛弃该点。如果迭代过程中有偏移量小于0.5,则停止迭代。
把该极值点带入到原公式中,则得到极值点所在的函数值:
\begin{equation}
f(\hat{X}) = f(X_0) + \frac{1}{2}\frac{\partial f^{\rm T}}{\partial X} \hat{X}
\end{equation}
如果上式中得到的$f(\hat{X})$过小,即其响应值过小,这样的点易受噪声的干扰而变得不稳定,所以也要被删除,Lowe论文中阈值为0.03(设灰度值为0~1)。
消除边缘响应
有些极值点的位置是在图像的边缘位置的,因为图像的边缘点很难定位,同时也容易受到噪声的干扰,我们把这些点看做是不稳定的极值点,需要进行去除。
由于图像中的物体的边缘位置的点的主曲率一般会比较高,因此我们可以通过主曲率来判断该点是否在物体的边缘位置。
某像素点位置处的主曲率可以由二维的Hessian矩阵计算得到:
\begin{equation}
H = \left[\begin{matrix}D_{xx}(x,y)&D_{xy}(x,y)\D_{xy}(x,y)&D_{yy}(x,y)\end{matrix}\right]
\end{equation}
设该矩阵的两个特征值分别为$\alpha$和$\beta$,其中$\alpha = \gamma\beta$,有如下公式:
\begin{align}
{\rm Tr}(H) = \alpha +\beta\
{\rm Det}(H) = \alpha\beta
\end{align}
其中${\rm Tr}(H)$表示矩阵的迹,${\rm Det}(H)$表示的矩阵的行列式。首先需要去除行列式为负的点。接下来需要去掉主曲率比较大的点,Lowe中使用如下判断规则:
\begin{equation}
\frac{ {\rm Tr}(H)^2}{ {\rm Det}(H)} = \frac{(\gamma\beta+\beta)^2}{\gamma\beta^2} = \frac{(\gamma+1)^2}{\gamma}
\end{equation}
这里$\gamma$越大,则表示该点越有可能在边缘,因此要检查主曲率是否超过一定的阈值$\gamma_0$,只需要判断:
\begin{equation}
\frac{ {\rm Tr}(H)^2}{ {\rm Det}(H)} < \frac{(\gamma_0+1)^2}{\gamma_0}
\end{equation}
Lowe论文中阈值为10。
特征点方向确定
上面我们已经找到了特征点。为了实现图像旋转不变性,需要根据检测到的特征点局部图像结构为特征点方向赋值。我们使用图像的梯度直方图法求特征点局部结构的稳定方向。
梯度方向和幅值
在前文中,精确定位关键点后也找到特征点的尺度值$\sigma$,根据这一尺度值,得到最接近这一尺度值的高斯图像:
\begin{equation}
L(x,y) = G(x,y,\sigma)\otimes I(x,y)
\end{equation}
使用有限差分,计算以特征点为中心,以$3\times1.5\sigma$为半径的区域内图像梯度的幅值$m(x,y)$和幅角$\theta(x,y)$,公式如下:
\begin{align}
m(x,y) &= \sqrt{(L(x+1, y) - L(x-1,y))^2+(L(x,y+1)-L(x,y-1))^2} \
\theta(x,y) &= {\rm arctan}\left[\frac{L(x,y+1)-L(x,y-1)}{L(x+1,y)-L(x-1,y)}\right]
\end{align}
梯度直方图
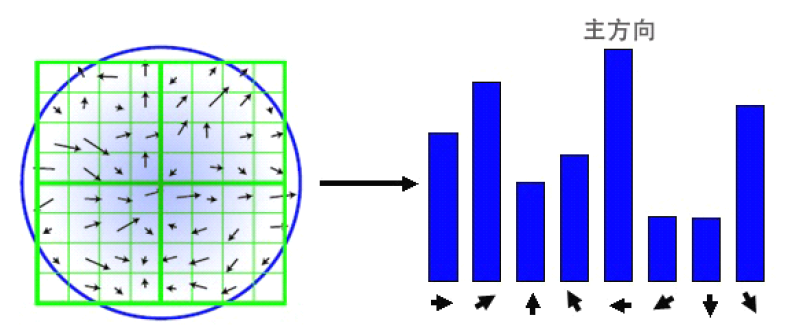
在完成特征点邻域内高斯图像梯度计算后,使用直方图统计邻域内像素对应的梯度方向和幅值。
梯度方向直方图的横轴是梯度方向角,纵轴是梯度方向角对应的梯度幅值累加值((为简化,图中只画了八个方向的直方图))。梯度方向直方图将0°~360°的范围分为36个柱,每10°为一个柱。可看作一定区域内的图像像素点对特征点方向生成所作的贡献。
在计算直方图时,每个加入直方图的采样点都使用圆形高斯函数函数进行了加权处理,也就是进行高斯平滑。Lowe建议子区域的像素的梯度大小$\sigma=0.5d$的高斯加权计算。这主要是因为SIFT算法只考虑了尺度和旋转不变形,没有考虑仿射不变性。通过高斯平滑,可以使关键点附近的梯度幅值有较大权重,从而部分弥补没考虑仿射不变形产生的特征点不稳定。通常离散的梯度直方图要进行插值拟合处理,以求取更精确的方向角度值。
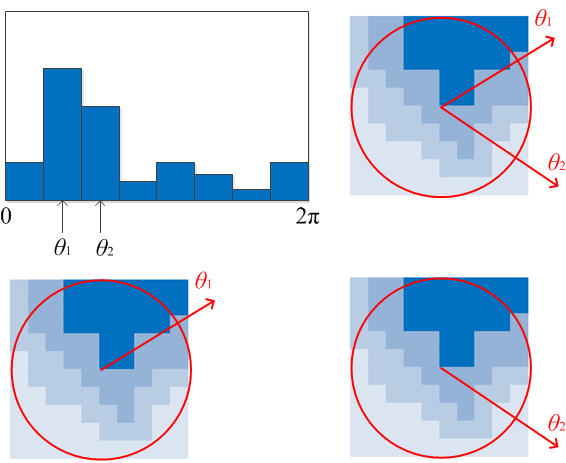
特征点方向
直方图峰值代表该特征点处邻域内图像梯度的主方向,也就是该特征点的主方向。在梯度方向直方图中,当存在另一个相当于主峰值80%能量的峰值时,则将这个方向认为是该特征点的辅方向。所以一个特征点可能检测得到多个方向,这可以增强匹配的鲁棒性。Lowe的论文指出大概有15%特征点具有多方向,但这些点对匹配的稳定性至为关键。获得图像特征点主方向后,每个特征点有三个信息$(x,y,\sigma,\theta)$:位置、尺度、方向。由此我们可以确定一个SIFT特征区域。通常使用一个带箭头的圆或直接使用箭头表示SIFT区域的三个值:中心表示特征点位置,半径表示特征点尺度($r=2.5\sigma$),箭头表示主方向。具有多个方向的特征点可以复制成多份,然后将方向值分别赋给复制后的特征点。如下图:
特征点描述
上文找到的SIFT特征点包含位置、尺度和方向的信息。接下来的步骤是特征点描述,即用一组向量将这个特征点描述出来,这个描述子不但包括特征点,也包括特征点周围对其有贡献的像素点,用来作为目标匹配的依据(所以描述子应该有较高的独特性,以保证匹配率),也可使特征点具有更多的不变特性,如光照变化、3D视点变化等。
SIFT描述子$h(x,y,\theta)$是对特征点附近邻域内高斯图像梯度统计的结果,是一个三维矩阵,但通常用一个矢量来表示。特征向量通过对三维矩阵按一定规律排列得到。
描述子采样区域
特征描述子与特征点所在尺度有关,因此对梯度的求取应在特征点对应的高斯图像上进行。
将特征点附近划分成$d^2$个子区域,每个子区域尺寸为$m\sigma$个像元($d=4$,$m=3$,$\sigma$为特征点的尺度值)。考虑到实际计算时需要双线性插值,故计算的图像区域为$m\sigma(d+1)$,再考虑旋转,则实际计算的图像区域为$\sqrt{2}m\sigma(d+1)/2$,如下图所示:
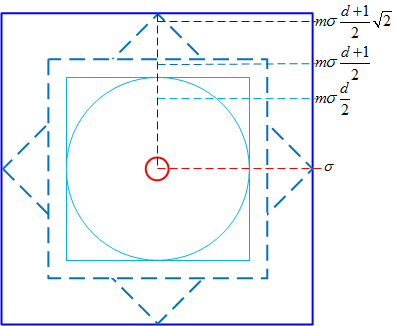
区域坐标轴旋转
为了保证特征矢量具有旋转不变性,要以特征点为中心,在附近邻域内旋转角,即旋转为特征点的方向。
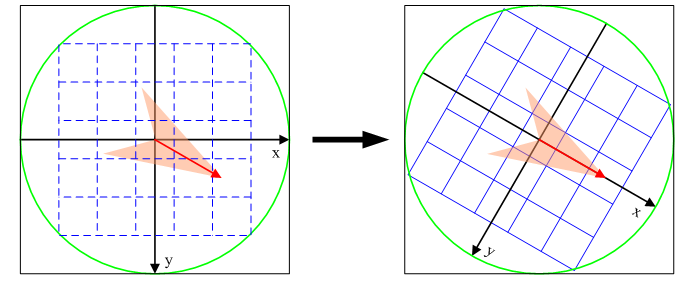
旋转后区域内采样点新的坐标为:
\begin{equation}
\begin{pmatrix} x’ \ y’\end{pmatrix} = \begin{pmatrix} cos\theta & -sin\theta \ sin\theta & cos\theta\end{pmatrix} \begin{pmatrix} x \ y\end{pmatrix}
\end{equation}
计算采样区域梯度直方图
将旋转后区域划分为$d^2$个子区域(每个区域间隔为$m\sigma$像元),在子区域内计算8个方向的梯度直方图,绘制每个方向梯度方向的累加值,形成一个种子点。 与求主方向不同的是,此时,每个子区域梯度方向直方图将0°~360°划分为8个方向区间,每个区间为45°。即每个种子点有8个方向区间的梯度强度信息。由于存在$d^2$,即16个子区域,所以最终共有128个数据(Lowe建议的数据),形成128维SIFT特征矢量。
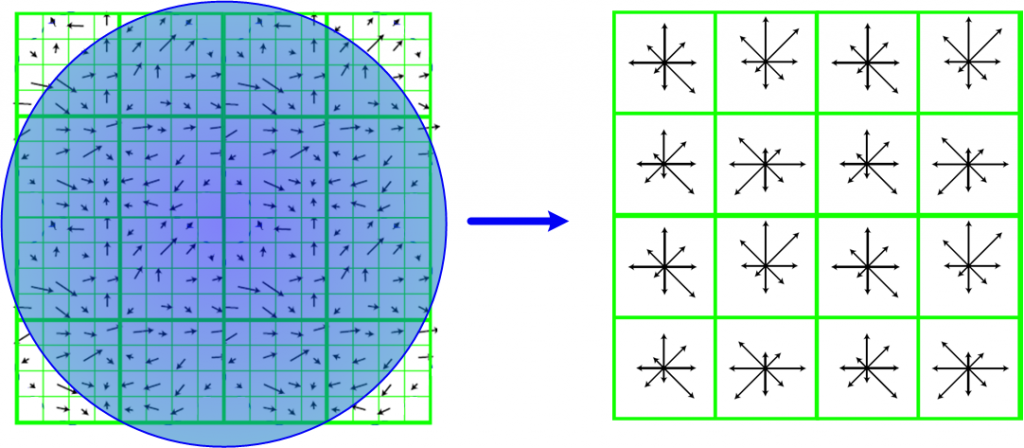
对特征矢量需要加权处理,加权采用$m\sigma d/2$的标准高斯函数。为了除去光照变化影响,还有进一步归一化处理。
至此SIFT描述子生成,SIFT算法也基本完成了。
Reference
[1] Lowe, David G. “Object recognition from local scale-invariant features.” Proceedings of the seventh IEEE international conference on computer vision. Vol. 2. Ieee, 1999.
[2] Lowe, David G. “Distinctive image features from scale-invariant keypoints.” International journal of computer vision 60.2 (2004): 91-110.