Python在科研中的应用 02:函数、流程控制语句与NumPy初步

通过前面两周课程的学习,我们了解了现代科研体系中编程语言的必要作用,而Python等解释型语言由于其便捷易开发的优势又是其中的主力军之一。以及对Python语言的基础知识包括注释、对象类型(数字、字符串、布尔型等)、运算符(位运算符、赋值运算符、逻辑运算符)等。第三周课程我们将学习Python语言编写时的缩进规则、函数的用法、流程控制语句以及NumPy模块的初步使用。
Python语言缩进规则
和其它程序设计语言采用大括号 {} 分隔代码块不同,Python 采用代码缩进和冒号来区分代码块之间的层次。 要求严格的代码缩进是Python语法的一大特色,好比C语言中的花括号一样重要。
在 Python 中,对于 $\lfloor$类$\rceil$、$\lfloor$函数$\rceil$、$\lfloor$流程控制语句$\rceil$、$\lfloor$异常处理语句$\rceil$ 等,行尾的冒号和下一行的缩进,表示下一个代码块的开始,而缩进的结束则表示此代码块的结束。
在python中,强制要求缩进,一般使用Tab或Space来进行缩进,且缩进必须要保持一致,否则可能会出缩进的错误。官方规定是缩进四个空格,而Tab键不一定等于四个空格,所以需要设置一个Tab等于四个空格。
1 | def dataInfo(filename,showInfor=False): |
与其他语言不同,Python属于强制缩进的,它这种做法属于双刃剑,有好处也有坏处。
好处是强迫你写出格式化的代码,但没有规定缩进是几个空格还是Tab。按照约定俗成的管理,应该始终坚持使用四个空格的缩进;另一个好处是强迫你写出缩进较少的代码,你会倾向于将一段很长的代码拆分成若干函数,从而得到缩进较少的代码。
坏处就是复制、粘贴功能失效了,当你重构代码时,粘贴过去的代码必须重新检查缩进是否正确;此外,IDE很难像格式化Java代码那样格式化Python代码。
本章小结
Python使用缩进来组织代码块,区分$\lfloor$类$\rceil$、$\lfloor$函数$\rceil$、$\lfloor$流程控制语句$\rceil$、$\lfloor$异常处理语句$\rceil$等的层次,请务必遵守约定俗成的习惯,坚持使用4个空格的缩进。在文本编辑器中,需要设置把
Tab自动转换为4个空格,确保不混用tab和空格。
Python 流程控制语句
我们可以使用 Python 来执行一些稍复杂的任务。例如,我们可以写一个生成菲波那契子序列的程序,如下所示:
1 | # Fibonacci series: |
这个例子介绍了几个新功能。
第一行包括了一个 多重赋值:变量 a 和 b 同时获得了新的值 0 和 1 最后一行又使用了一次。在这个演示中,变量赋值前,右边首先完成计算。右边的表达式从左到右计算。
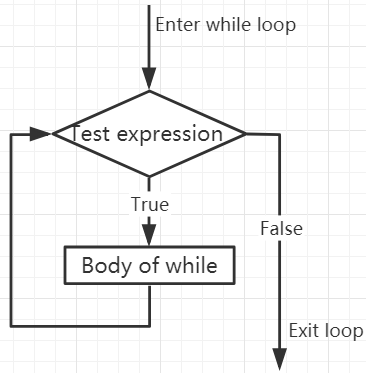
条件(这里是 b < 10 )为 true 时, while 循环执行。在 Python 中,类似于 C,任何非零整数都是 True;0 是 False。条件也可以是字符串或列表,实际上可以是任何序列;
循环体是缩进的:缩进是 Python 组织语句的方法。
除了这里介绍的 while 语句,Python 还从其它语言借鉴了一些流程控制功能,并有所改变。
if 语句
也许最有名的是 if 语句。例如:
1 | x = int(input("Please enter an integer: ")) |
可能会有零到多个elif部分,else是可选的。关键字elif是else if的缩写,这个可以有效地避免过深的缩进。`if … elif … elif …`` 序列用于替代其它语言中的 switch 或 case 语句。
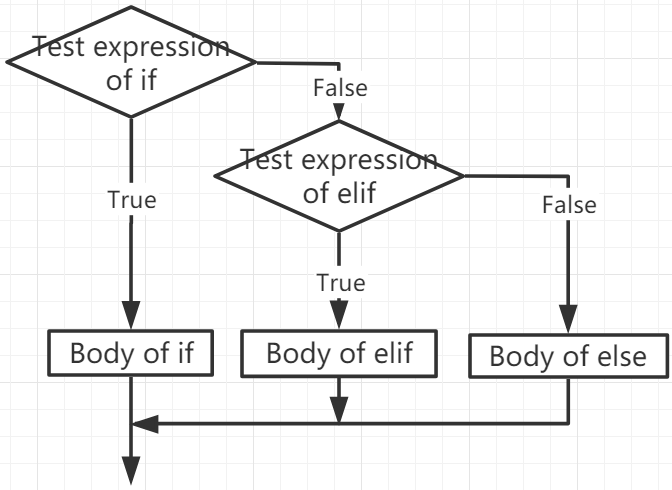
我们可以将一个if语句嵌入到另一个if语句中,然后称之为嵌套if语句。事实上,所有的流程控制语句都可以多层嵌套。例如:
1 | x = 67 |
for 语句
Python 中的 for 语句和 C 或 Pascal 中的略有不同。通常的循环可能会依据一个等差数值步进过程(如 Pascal),或由用户来定义迭代步骤和中止条件(如 C ),Python 的 for 语句依据任意序列(链表或字符串)中的子项,按它们在序列中的顺序来进行迭代。例如:
1 | # Measure some strings: |
在迭代过程中修改迭代序列不安全(只有在使用链表这样的可变序列时才会有这样的情况)。如果你想要修改你迭代的序列(例如,复制选择项),你可以迭代它的复本。使用切割标识就可以很方便的做到这一点:
1 | for w in words[:]: # Loop over a slice copy of the entire list. |
range() 函数
如果你需要一个数值序列,内置函数range()会很方便,它生成一个等差级数链表:
1 | for i in range(5): |
range(10)生成了一个包含 10 个值的链表,它用链表的索引值填充了这个长度为 10 的列表,所生成的链表中不包括范围中的结束值。也可以让 range() 操作从另一个数值开始,或者可以指定一个不同的步进值(甚至是负数,有时这也被称为 “步长”):
1 | range(5, 10) |
需要迭代链表索引的话,如下所示结合使用range()和len():
1 | a = ['Mary', 'had', 'a', 'little', 'lamb'] |
不过,这种场合可以方便的使用enumerate()。在序列中循环时,索引位置和对应值可以使用enumerate()函数同时得到:
1 | for i, v in enumerate(['tic', 'tac', 'toe']): |
如果你只是打印一个序列的话会发生奇怪的事情:
1 | >>> print(range(10)) |
在不同方面 range() 函数返回的对象表现为它是一个列表,但事实上它并不是。当你迭代它时,它是一个能够像期望的序列返回连续项的对象;但为了节省空间,它并不真正构造列表。
我们称此类对象是 可迭代的,即适合作为那些期望从某些东西中获得连续项直到结束的函数或结构的一个目标(参数)。我们已经见过的 for 语句就是这样一个迭代器。list() 函数是另外一个( 迭代器 ),它从可迭代(对象)中创建列表:
1 | list(range(5)) |
以后的学习中我们会看到更多返回可迭代(对象)和以可迭代(对象)作为参数的函数。
break 和 continue 语句, 以及循环中的 else 子句
break 语句和 C 中的类似,用于跳出最近的一级 for 或 while 循环。
循环可以有一个 else 子句;它在循环迭代完整个列表(对于 for )或执行条件为 false (对于 while )时执行,但循环被 break 中止的情况下不会执行。以下搜索素数的示例程序演示了这个过程:
1 | for n in range(2, 10): |
(Yes, 这是正确的代码。看仔细:else 语句是属于 for 循环之中, 不是 if 语句。)
- 与循环一起使用时,else 子句与 try 语句的 else 子句比与 if 语句的具有更多的共同点:try 语句的 else 子句在未出现异常时运行,循环的 else 子句在未出现 break 时运行。
continue 语句是从 C 中借鉴来的,它表示循环继续执行下一次迭代:
1 | for num in range(2, 10): |
pass 语句
pass 语句什么也不做。它用于那些语法上必须要有什么语句,但程序什么也不做的场合,例如:
1 | while True: |
这通常用于创建最小结构的类:
1 | class MyEmptyClass: |
另一方面,pass 可以在创建新代码时用来做函数或控制体的占位符。可以让你在更抽象的级别上思考。pass 可以默默的被忽视:
1 | def initlog(*args): |
本章小结
通过本节的学习,我们了解了Python中的流程控制语句,包括if … elif … else …结构,while结构以及for循环的基本使用方法,以及与之配合的range()函数及break\continue语句的使用规则。
Python语言中的函数
在编程中,函数是一种模块化的手段,当它被调用时执行特定功能并提供反馈。可提高代码的利用率,避免重复代码,便于使用,便于维护。Python 中,不仅提供了许多现成可用的内建函数,用户还可以根据自己的需求,定义自己的函数。
函数也属于一种数据类型,可以使用type()查看,内建函数为builtin_function_or_method,自定义函数为function。
1 | def printhello(): # 自定义函数 test(),并没有实质功能 |
本章节将展示如何在Python中定义函数并调用它,这样你就可以把Python应用程序的代码模块化分解,重复利用,精简代码结构。
创建函数
创建函数也称为定义函数,可以理解为创建一个具有某种用途的工具,通过def关键词及函数标识符(函数对象名)实现,具体的语法格式如下:
1 | def functionName(parameterList): |
这里包括四个函数的基本元素:
- functionName: 函数名称,在调用函数时使用。
- parameterlist: 可选参数,用于指定像函数中传递的参数。如果有多个参数,则各参数间使用逗号
,分隔;如果不指定,则表示该函数没有输入参数。 - comments: 可选参数,标识为函数指定注释。也称为Docstrings(文档字符串),通常用于说明该函数的功能、要传递的参数的作用等等。
- functionBody: 函数体,实现函数的功能的具体代码块。如果函数有返回值,可以使用return语句返回。
函数体“functionBody”与注释“comments”相对于def关键字必须保持缩进。
按照上面的基本语法,一个向终端输出随机生成的两个变量之和的Python函数示例如下所示:
1 | def myfunction(): |
我们举一个工程应用中具体的例子:
1 | def update_image(self, geo, angle, iteration): |
在Python2.X的版本中,如果定义的函数暂时什么都不做,那么需要使用pass关键字作为点位符,或者添加Docstrings,但不可以直接添加一行单行注释,示例如下:
1 | def functionNull(): |
调用函数
调用函数也就是执行函数,调用函数的基本语法格式如下:
1 | functionNmae(parameterValue) |
共包括两个基本元素:
- functionName: 函数名称,要调用的函数名称必须是已经创建好的。
- parameterValue: 指定函数需求输入的各个参数的值。如果有多个参数,则各参数间使用逗号
,分隔;如函数无需参数输入,也必须写一对小括号在此。
例如调用一个向终端输出两个随机变量之和的Python函数示例如下所示:
1 | def myfunction(): |
在Python中我们可以使用return关键字,从函数中向外反馈一些参数。return语句可以包含一个要执行的表达式。下面的例子演示了return关键字在 Python 中的作用:
1 | def multiplyNum(num1): |
函数中的参数
在 Python 中,你也可以定义包含若干参数的函数。这里有三种可用的形式,也可以混合使用。第一种就是规规矩矩的按照位置准确传递参数。
1 | def ask_ok(prompt, retries, complaint): |
默认参数值
此外最常用的一种形式是为一个或多个参数指定默认值。这会创建一个可以使用比定义时允许的参数更少的参数调用的函数,例如:
1 | def ask_ok(prompt, retries=4, complaint='Yes or no, please!'): |
这个函数可以通过几种不同的方式调用:
1 | # 只给出必要的参数: |
这个例子还介绍了in关键字。它测定序列中是否包含某个确定的值。
默认值在函数定义作用域被解析,如下所示:
1 | i = 5 |
重要警告: 默认值只被赋值一次。这使得当默认值是可变对象时会有所不同,比如列表、字典或者大多数类的实例。例如,下面的函数在后续调用过程中会累积(前面)传给它的参数:
1 | def f(a, L=[]): |
如果你不想让默认值在后续调用中累积,你可以像下面一样定义函数:
1 | def f(a, L=None): |
关键字参数
函数可以通过 关键字参数 的形式来调用,形如 keyword = value。例如,以下的函数:
1 | def parrot(voltage, state='a stiff', action='voom', type='Norwegian Blue'): |
接受一个必选参数 (voltage) 以及三个可选参数 (state, action, 和 type)。可以用以下的任一方法调用:
1 | parrot(1000) # 1 positional argument |
不过以下几种调用是无效的:
1 | parrot() # required argument missing |
在函数调用中,关键字的参数必须跟随在位置参数的后面。传递的所有关键字参数必须与函数接受的某个参数相匹配 (例如 actor 不是 parrot 函数的有效参数),它们的顺序并不重要。这也包括非可选参数(例如 parrot(voltage=1000) 也是有效的)。任何参数都不可以多次赋值。下面的示例由于这种限制将失败:
1 | >> def function(a): |
以下为可选阅读:
引入一个形如 **name 的参数时,它接收一个字典(参见 下一小节 ),该字典包含了所有未出现在形式参数列表中的关键字参数。这里可能还会组合使用一个形如 *name (下一小节详细介绍) 的形式参数,它接收一个元组(下一节中会详细介绍),包含了所有没有出现在形式参数列表中的参数值( *name 必须在 **name 之前出现)。 例如,我们这样定义一个函数:
1 | def cheeseshop(kind, *arguments, **keywords): |
它可以像这样调用:
1 | cheeseshop("Limburger", "It's very runny, sir.", |
当然它会按如下内容打印:
1 | -- Do you have any Limburger ? |
注意在打印关键字参数之前,通过对关键字字典keys()方法的结果进行排序,生成了关键字参数名的列表;如果不这样做,打印出来的参数的顺序是未定义的。
可变参数列表
最后,一个最不常用的选择是可以让函数调用可变个数的参数。这些参数被包装进一个元组。在这些可变个数的参数之前,可以有零到多个普通的参数:
1 | def write_multiple_items(file, separator, *args): |
通常,这些 可变 参数是参数列表中的最后一个,因为它们将把所有的剩余输入参数传递给函数。任何出现在*args后的参数是关键字参数,这意味着,他们只能被用作关键字,而不是位置参数:
1 | def concat(*args, sep="/"): |
另一种形式是**arg作为关键词,表示接受任意多个显式赋值的实际参数,并将其放在一个字典之中。例如:
1 | def bar(param1, **param2): |
当然这两种用法可以同时出现在一个函数之中:
1 | def foo(a, b=10, *args, **kwargs): |
参数列表的分拆
当大家在阅读如《Python从入门到精通》等丛书时,通常会介绍到当我们尝试把元组或字典直接输入给函数,可以分别使用*arg或**arg直接向函数输入。但这是为什么呢?
当你要传递的参数已经是一个列表,但要调用的函数却接受分开一个个的参数值。这时候你要把已有的列表拆开来。例如内建函数range()需要要独立的 start,stop参数。你可以在调用函数时加一个 * 操作符来自动把参数列表拆开:
1 | list(range(3, 6)) # normal call with separate arguments |
以同样的方式,可以使用 ** 操作符分拆关键字参数为字典:
1 | def parrot(voltage, state='a stiff', action='voom'): |
Lambda 形式
出于实际需要,有几种通常在函数式编程语言例如 Lisp 中出现的功能加入到了 Python。通过lambda关键字,可以创建短小的匿名函数。这里有一个函数返回它的两个参数的和: lambda a, b: a+b。 Lambda 形式可以用于任何需要的函数对象。出于语法限制,它们只能有一个单独的表达式。语义上讲,它们只是普通函数定义中的一个语法技巧。类似于嵌套函数定义,lambda 形式可以从外部作用域引用变量:
1 | def make_incrementor(n): |
函数中的参数传递深入解析
在Python中定义一个函数时,可以通过把参数放在括号内将它们传入函数。调用函数时,需要为参数指定一个值:
1 | def addNum(num1, num2): |
在上面的例子中,我向名为addNum的函数传递了两个参数,该函数将两个参数的和输出至终端。
定位参数、关键字参数
在Python中,当定义一个函数时,函数接收的参数叫做形式参数(parameters),以下简称形参;当调用一个函数时,调用语句传递给该函数的值叫做实际参数(arguments),以下简称实参。
根据$\lfloor$inspect模块$\rceil$ 的描述,Python的形参可以分成如下五类:
POSITIONAL_OR_KEYWORD,默认类型,可通过定位/关键字实参传递;VAR_POSITIONAL,定位形参元祖,如*args,捕获剩下的定位实参;KEYWORD_ONLY,在*或*args之后的形参,只能通过关键字实参传递;VAR_KEYWORD,关键字形参字典,如**kwargs,捕获剩下的关键字实参;POSITIONAL_ONLY,只能通过定位实参传递,Python语法暂不支持,只有一些C函数(如divmod)使用。
比如定义如下函数:
1 | def foo(a, *args): |
其中形参a属于POSITIONAL_OR_KEYWORD,可通过定位/关键字实参传递:
1 | foo(1) |
满足形参a之后,剩余的定位实参将被*args以元组的形式捕获:
1 | foo(1, 2, 3) |
再比如定义如下函数:
1 | def foo(a, *args, b, **kwargs): |
形参b属于KEYWORD_ONLY,因为它在*args之后定义:
1 | foo(1, b=2) |
满足形参b之后,剩余的关键字实参将被**kwargs以字典的形式捕获:
1 | foo(1, b=2, c=3) |
如果想定义KEYWORD_ONLY形参,但不想使用VAR_POSITIONAL形参(即*args),则可以在定义函数时单独的*号:
1 | def foo(a, *, b): |
参数默认值
在定义函数时,我们可以给形参指定默认值,比如:
1 | def foo(a=1, *args, b=2, **kwargs): |
需要注意的是,形参的默认值存储在函数对象的__defaults__和__kwdefaults__属性里,而不是每次调用函数时动态生成,所以最好不要用可变对象充当形参的默认值。下面的例子就是反面教材:
1 | def foo(param=[]): |
获取关于参数的信息
内省指程序在运行时检查对象类型的一种能力,本节介绍的内容就属于函数内省的范围。假设有如下函数:
1 | def foo(a=1, *args, b=2, **kwargs): |
就像上一节中提到的,foo函数有__defaults__、__kwdefaults__属性,用于记录定位参数和关键字参数的默认值;有__code__属性,存储函数编译后的字节码信息,其中就包括参数的名称。通过这些属性,我们可以获取关于函数参数的信息:
1 | foo.__defaults__ |
但这样还是太原始、太不方便了。幸好,我们有更好的选择:Python内置的inspect模块。下面这个例子就提取了foo函数的签名,然后获取函数的参数信息:
1 | from inspect import signature |
同时,inspect.Signature对象还有一个bind方法,该方法可以将一些对象绑定到函数的形参上,就像Python解释器在调用函数时做的那样。通过这种方法,框架可以在真正执行函数前验证参数,就像下面这个例子:
1 | bound = sig.bind(1, 2, 3, c=3) |
函数参数传递
说起函数参数传递,可能就有人想起了引用传递、值传递……忘掉这两个概念,来看看下面两个例子:
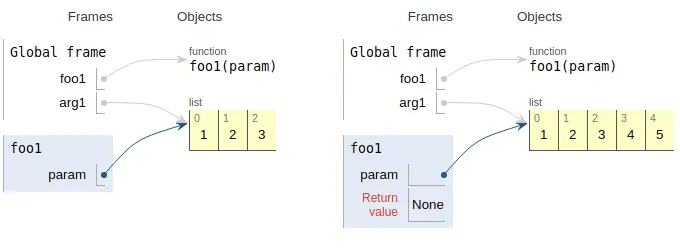
1 | def foo1(param: list): |
内存中有一个list对象([1, 2, 3]),该对象有两个别名:arg1和param。由于list对象是可变的(mutable),所以可以通过param这个别名修改这个list对象的内容。
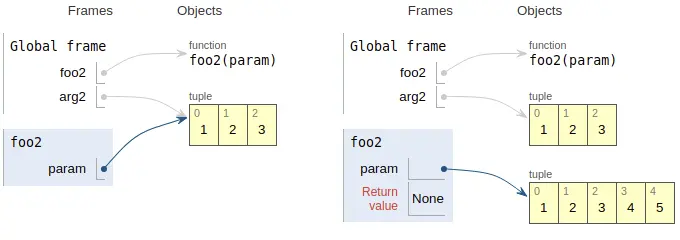
1 | def foo2(param: tuple): |
内存中有一个tuple对象((1, 2, 3)),该对象也有两个别名:arg2和param。但由于tuple对象是不可变的(immutable),当执行param += (4, 5)时,解释器创建了一个新的tuple对象((1, 2, 3, 4, 5)),并让param指向这个新的对象,而原来的对象没有被改变。
在Python中,参数传递本质上是为已有的对象取了一个函数作用域级别的别名。如果该对象是可变的,那么就可以在函数内修改该对象,这种修改也可以被其它的别名所感知。弄清楚对象、别名的关系,就不会对值传递、引用传递这种说法感到困惑了。
NumPy初步
NumPy是Python中科学计算的基本软件包。它是一个Python库,提供多维数组对象,各种派生对象(例如蒙版数组和矩阵)以及各种例程,用于对数组进行快速操作,包括数学,逻辑,形状处理,排序,选择,I/O,离散傅立叶变换,基本线性代数,基本统计运算,随机模拟等等。
NumPy安装
安装NumPy的唯一前提是Python本身。而Python官网上的发行版是不包含NumPy模块的。如果你希望以最简单的方式开始使用,建议你使用Anaconda发行版,它包括Python,NumPy和许多其他用于科学计算和数据科学常用的软件包。同时支持Linux、Windows和mac。
如果你没有NumPy,在windows平台的cmd窗口可以通过如下命令执行安装:
1 | pip3 install numpy |
默认情况使用国外线路,如果太慢,我们使用清华的镜像就可以:
1 | pip3 install numpy -i https://pypi.tuna.tsinghua.edu.cn/simple |
Mac 系统的 Homebrew 不包含 NumPy 或其他一些科学计算包,同样可以采用以下方式进行安装。打开终端,输入:
1 | pip3 install numpy -i https://pypi.tuna.tsinghua.edu.cn/simple |
完成安装后,你可以进行验证:
1 | import numpy as np |
NumPy的历史可以追溯到90年代中期,它的前身为Numeric(用C语言编写,主要用来调取C++中应用)和Numarray(用于处理高维数组,可灵活的索引、数据类型变换、广播等),2005年出现的NumPy作为继承者,吸取了Numeric中丰富的C API及Numarray的高维数组处理能力,成为Python科学计算生态系统的基础。追根溯源,NumPy是集成在Python编程语言中的向量化运算工具集,如果你是用的是Intel的CPU,它将直接调用MKL库执行C语言的向量计算库,这是目前速度最快的向量计算库。
将大规模向量、矩阵运算交给NumPy如果对数组进行向量化运算,例如全体四则运算、矩阵乘法、求和、按指标求和等,一定要利用NumPy的矩阵运算。
1 | import numpy as np |
Python 代码的性能分析
我们怎样知道执行某个Python文件、某个函数、某段代码所耗费的总体时间?
作为样例,本文使用slow_func.py来进行性能分析,内容如下:
1 | # coding:utf-8 |
函数func1和func2的区别在于:CPU在执行func1时基本处在闲置状态,在执行func2()时基本处于忙碌状态。这点会在之后的测试中有所体现。在笔者的测试平台(Ubuntu 18.04+Python 3.6)上,两个函数所耗费的时间均在1s左右。
time命令
类UNIX平台提供了time命令以统计执行执行命令所花费的时间。当然,这是一个通用型的工具,而不局限于Python。
执行如下shell命令:
1 | time python3 slow_func.py |
获得如下结果:
1 | real 0m1.960s # 命令执行时间 |
根据前两行结果中我们可以得知,slow_func.py从开始到结束共消耗了2秒左右的时间,但实际消耗的用户态CPU时间只有1秒左右。这是因为CPU在执行func1()时处于等待状态(sleep),这段时间里是不消耗CPU时间的。
time库
Python提供了标准库time来进行关于时间的操作,我们可以通过这个库来测量代码执行所耗费的时间。
执行如下Python代码:
1 | import time |
time.perf_counter()的时间差是代码开始与代码结束两个时间点的时间差,而time.process_time()的时间差是消耗的CPU时间长度,所以得出了不同的结果,这与先前的time命令的原因和结果相类似。
time库+上下文管理器
上面提到的用time库来测量代码耗时用起来很方便,但如果经常要用到的话写起来也很繁琐。这时我们可以写一个自定义的上下文管理器来避免重复代码。
执行如下Python代码:
1 | import time |
time库+函数装饰器
上下文管理器针对的是代码块,如果只想统计函数执行所消耗的时间,用函数装饰器更为方便和快捷。
执行如下Python代码:
1 | import time |
timeit库
当需要多次重复测量Python代时以获取精确的耗时结果时,我们可以通过循环控制配合上文提到的方法来实现,也可以通过一个更便捷的、适合重复测试的标准库:timeit来实现。
执行如下代码:
1 | import timeit |
timeit库默认使用的计时器为time.perf_counter(),如果想换成测量CPU耗时的计时器,只需要附加上timer参数即可:
1 | import time |
cProfile
而在实际的性能分析场景中,目标代码的逻辑往往比较复杂,光靠总体执行耗时并不能帮助我们快速定位性能瓶颈。这个时候就需要请出Python的标准库:cProfile(官方文档)来对代码进行细致的性能分析了。
命令行使用cProfile
对于单独的Python代码文件来说,通过命令行使用cProfile无疑是最方便的选择。
执行如下shell命令:
1 | python3 -m cProfile -s tottime slow_func.py |
首先用python3的-m选项调用cProfile模块,然后用cProfile的-s选项让输出结果按tottime进行排序,最后执行slow_func.py文件。
完整调用格式为:python -m cProfile [-o output_file] [-s sort_order] myscript.py
得到如下结果:
1 | 16778563 function calls (16778520 primitive calls) in 3.176 seconds |
- 输出的第1行表明,脚本文件执行中存在1600多万次的函数调用,共耗费3.268秒。
** 而根据前一篇文章的测试结果,直接执行该脚本文件只需要2秒左右的时间,那多出来的1秒多花在了哪里?这是因为cProfile需要对每一次函数调用进行监控和记录,由于该文件存在较多的函数调用,所以总执行耗时也就增长了许多了。 - 第3行表明,下表内容按照internal time(内部执行时间,tottime)排序,这是由执行命令中的-s tottime参数决定的。
- 第5行为分析结果表的表头,依次为ncalls:调用次数、tottime:内部执行耗时、percall:内部执行耗时/调用次数、cumtime:累计执行耗时、percall:累计执行耗时/调用次数,以及最后的文件名+行号+函数名称。
** tottime和cumtime的区别在于,tottime不包括子函数执行所花费的时间,而cumtime是包括的。 - 第6行表明,slow_func.py中第8行的func2函数共执行了1次,内部耗时1.456秒,累计耗时2.172秒。
- 第7行表明,Python内置的sleep函数共执行了一次,耗时1.001秒。
- 第8行表明,Python内置的random函数共执行了1600多万次,耗时0.716秒。
** 由于random函数是被func2函数调用的,所以这0.716秒和func2函数的内部执行耗时1.456秒,共同组成了func2函数的累计执行耗时:2.172秒。 - 由于是用cProfile分析整个脚本文件,所以许多Python自身所需的函数调用也被展示在了结果里,所以分析结果表才会有100多行的规模。这个问题可以在下一小节中解决。
代码里使用cProfile
从本质上来说,通过命令行使用cProfile相当于在代码里使用cProfile的一个简化操作。而在命令行里分析代码有着明显的局限性:目标代码必须独立成文件、输出格式固定等等。所以,在代码里使用cProfile往往是一个更优的选择。
执行如下Python代码:
1 | import cProfile |
代码的核心逻辑是使用cProfile模块的Profile类对代码块进行性能分析,分析完成后使用pstats模块的Stats类将分析结果按一定格式写入至内存文件,最后输出该文件里写入的内容。
实际上这只是一个较为简单的样例,pstats模块还可以获得函数之间的调用关系、将结果持久化、显示文件路径等等,更完整的说明可以参考官方文档。
得到如下结果:
1 | 16777220 function calls in 3.225 seconds |
cProfile结果可视化
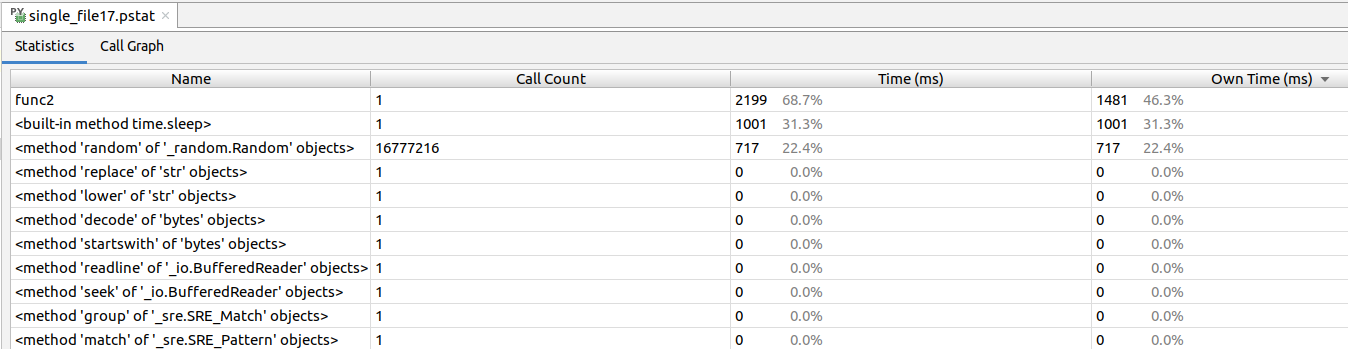
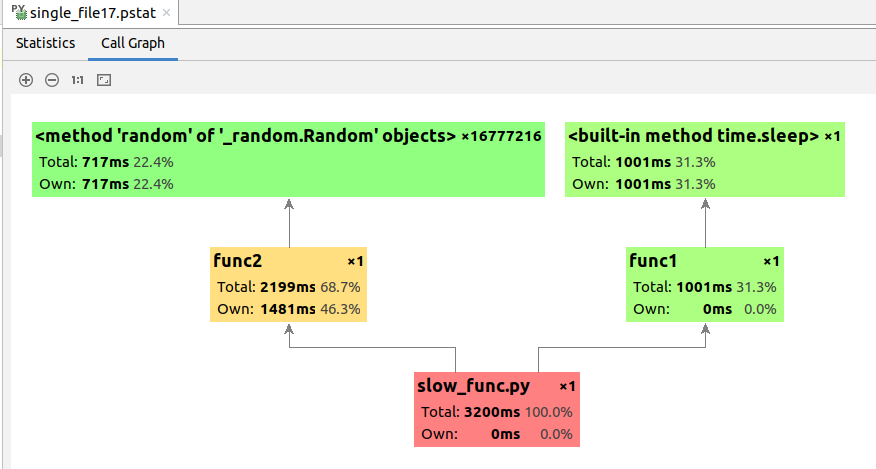
一般来说,通过以上两个例子就可以获得完善的性能分析报告了。但通过一些可视化工具对cProfile的报告进行二次处理,我们可以更清晰地观察函数之间的调用关系、更轻松地找出性能瓶颈,算是一个不错的辅助手段。在这里只介绍一种可视化工具:JetBrain PyCharm自带的Profile工具。
点击Pycharm中Run菜单里的Profile ‘xxx’项目,即可对当前运行执行方案使用cProfile进行性能分析,如下图:
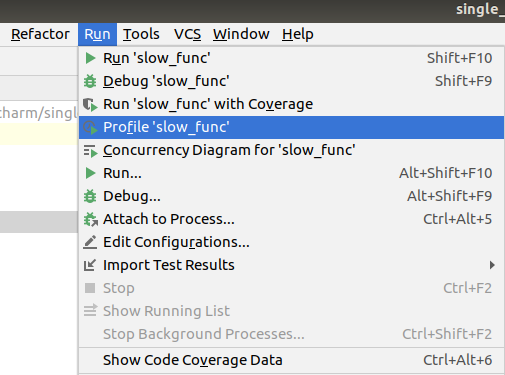
结果如下图所示。其中,Time对应cProfile中的cumtime,即累计执行耗时;Own Time对应cProfile中的tottime,即内部执行耗时。